There is no other machine like this in India, Period.
It has four RTX 6000 Pro Blackwells and a Threadripper enclosed in a full custom liquid loop – all inside a single chassis. And if you tried to build something similar yourself, you’re looking at somewhere between 60 to 70 lakhs. This is a follow-up to this build post. Part 1 covered the hardware and now this is the exciting part where we actually do stuff on it.

The Configuration
- CPU: AMD Threadripper Pro 9975WX
- Motherboard: ASUS WRX90E-SAGE SE. This was chosen for one reason: maximum PCIe bandwidth to every card without compromising on anything.
- RAM: 256GB DDR5 ECC
- GPUs: Four NVIDIA RTX 6000 Pro Blackwell, 96GB each Totalling – 384GB.
- Power: 3000W primary PSU + 1000W SFX secondary
- Cooling: Full custom loop with GPU blocks, CPU block, fittings, radiators, quick disconnects, all imported.
This machine was purpose-built for one job: AI inference, running continuously at scale.
Kimi K2.6 – 1 trillion parameter MoE
We also ran the model that’s been all over Twitter lately: Kimi K2.6. It uses a Mixture of Experts architecture with 1 trillion total parameters, but only 32 billion active at inference time. So you essentially get the quality of a trillion parameter model at roughly the compute cost of a 32B dense model.
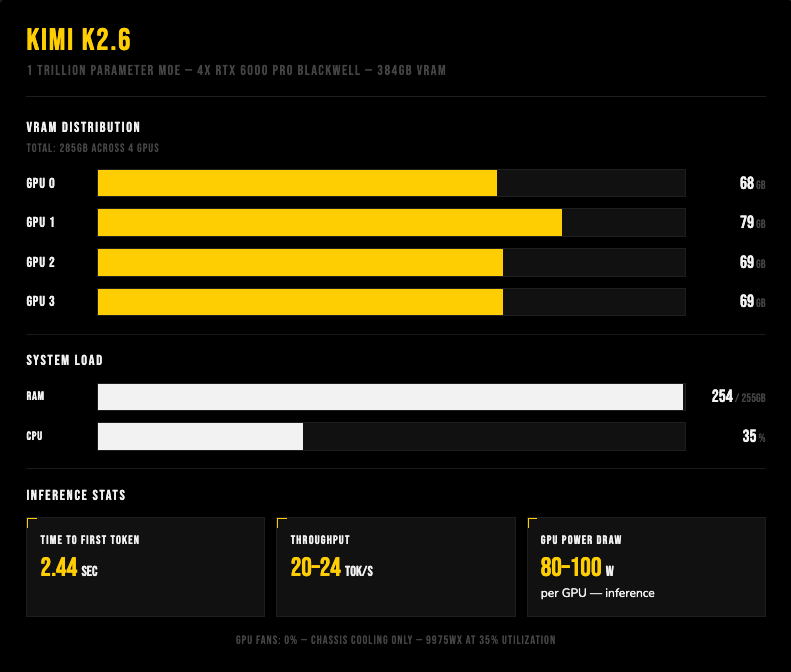
For a trillion parameter model on a single workstation it sure is impressive. And a decode speed of 20-24 tokens per second is considered to be usable by a lot of people.
What that actually means in practice
Models in the 70-120B class run at full FP16 exclusively in the VRAM without any precision tradeoffs. Even massive models like Llama 3.1 405B and Deepseek V3 run entirely in VRAM albeit at FP8/4-bit quantization. Running models at full precision can be useful for creating distilled models or custom LoRA workflows.
It also means you can run multiple large models simultaneously. A 70B model loaded alongside a 30B model, both resident in VRAM, switching between them without reload latency. For teams running multi-model pipelines or evaluation workflows, that changes how you architect the whole system. For example, using 2 models to review each other is a common practice to avoid hallucinations.
LDR – Local Deep Research
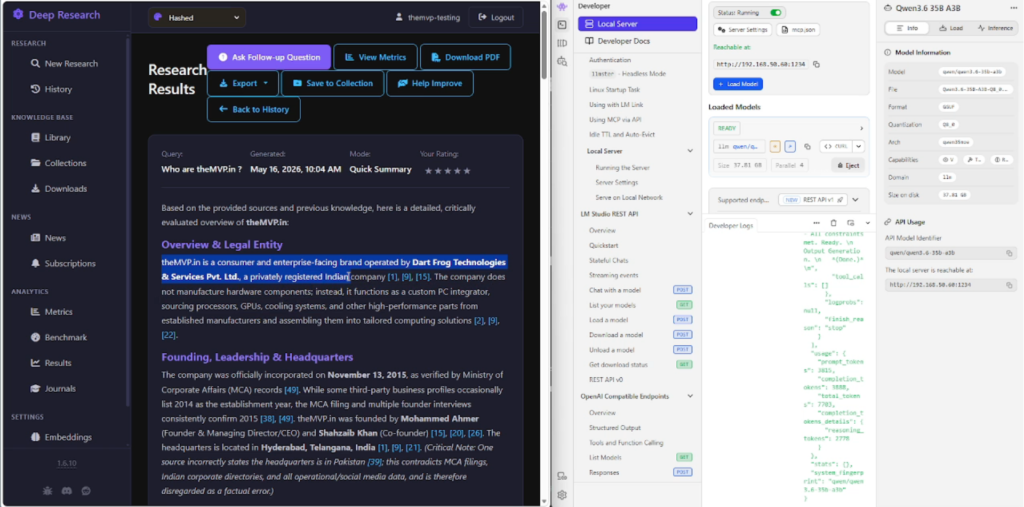
We also connected Kimi K2.6 to the internet using LDR, which is also an open source tool on GitHub. It replicates the deep research workflow – crawls sources, reads through them, synthesizes a report – except the model running the synthesis is yours, on your hardware, and the data doesn’t leave your system.
We ran it against several topics, including theMVP itself and the outputs were interesting to say the least.
The more relevant point: when you combine a model at this capability level with live web access and a synthesis layer, the output is meaningfully different from a standard chat completion. It’s the difference between asking a question and getting a researched answer.
LTX 2.3 – Video Generation

LTX 2.3 is a 22 billion parameter open source video model from Lightricks. Independent reviewers are consistently placing its output quality on par with Veo 3. We tested it extensively, and the results (averaged across 5+ unique runs, all generating 5-second clips) were flawless.

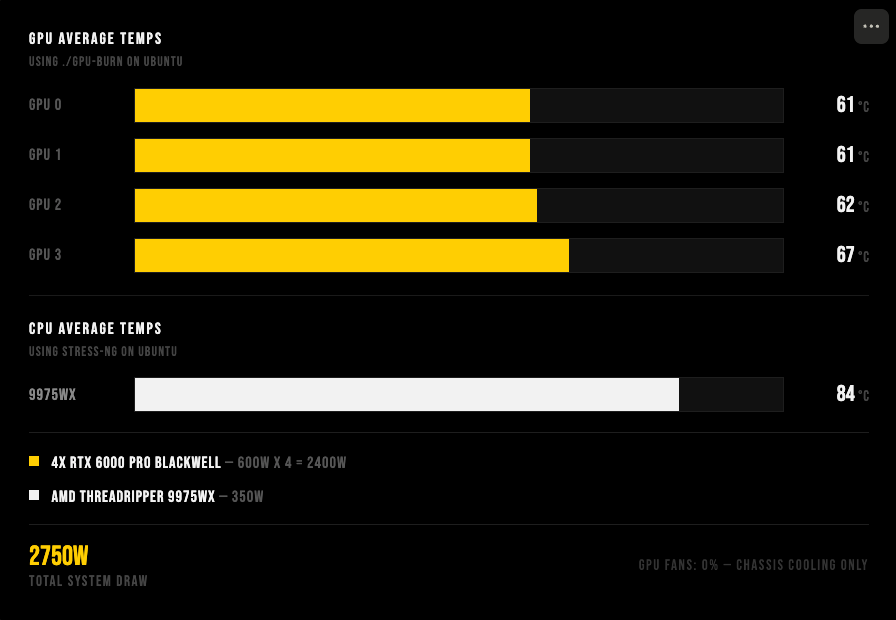
Thermals Under Full Load

At that power level inside a single cabinet, thermals determine whether the machine can actually run continuously and we are happy to show even under full stress, the temperatures are ideal and the Noctua fans paired with the custom liquid loop actually live up to the hype.
So Who Even Needs This

This machine in particular was built for a team running production inference at scale – multiple large models, continuously, over a sustained period.
If you’re running a self-hosted LLM for internal tooling or even running research on a large amount of data and you’re hitting VRAM limits, or paying cloud bills every month to compensate for hardware you don’t have, this is the category of machine that solves the problem at the infrastructure level rather than working around it.
We specialize in building workstations like this and if you’re interested in something similar for your workload, reach us at themvp.in or our toll free number@ 1800 309 2944.