Dall-E for Image Generation, ChatGPT for Text Generation
And now… Sora for Video Generation…
How is OpenAI always building the next killer AI app?
and what’s even more interesting is that – this… is OpenAI’s competition. the kind of videos they create don’t even come close to the quality of Sora’s videos
And this narrative plays out for all the previous models as well. You see OpenAI was never a first mover in the industry,
take GPT for example, the reason why LLMs became possible was because of a technique called “Attention” and this was developed by a google research team almost 5 years before ChatGPT.

Similarly Dall-E was based on a research paper released all the way back in 2015

Yet, everytime OpenAI has managed to build something that is miles ahead of the competition – so what’s the secret that helps them build the best Generative AI models…
It’s actually really simple – and that is GPUs…

Ok so before we get any further – let’s understand how Sora works. And they’re are 2 main techniques being used inside.
Transformer & Diffusion.
Transformer is the engine behind chatGPT, they are made to understand human language. So over here this is used to re-write your prompt in a much more visually descriptive way.
You’ll understand why in a minute.
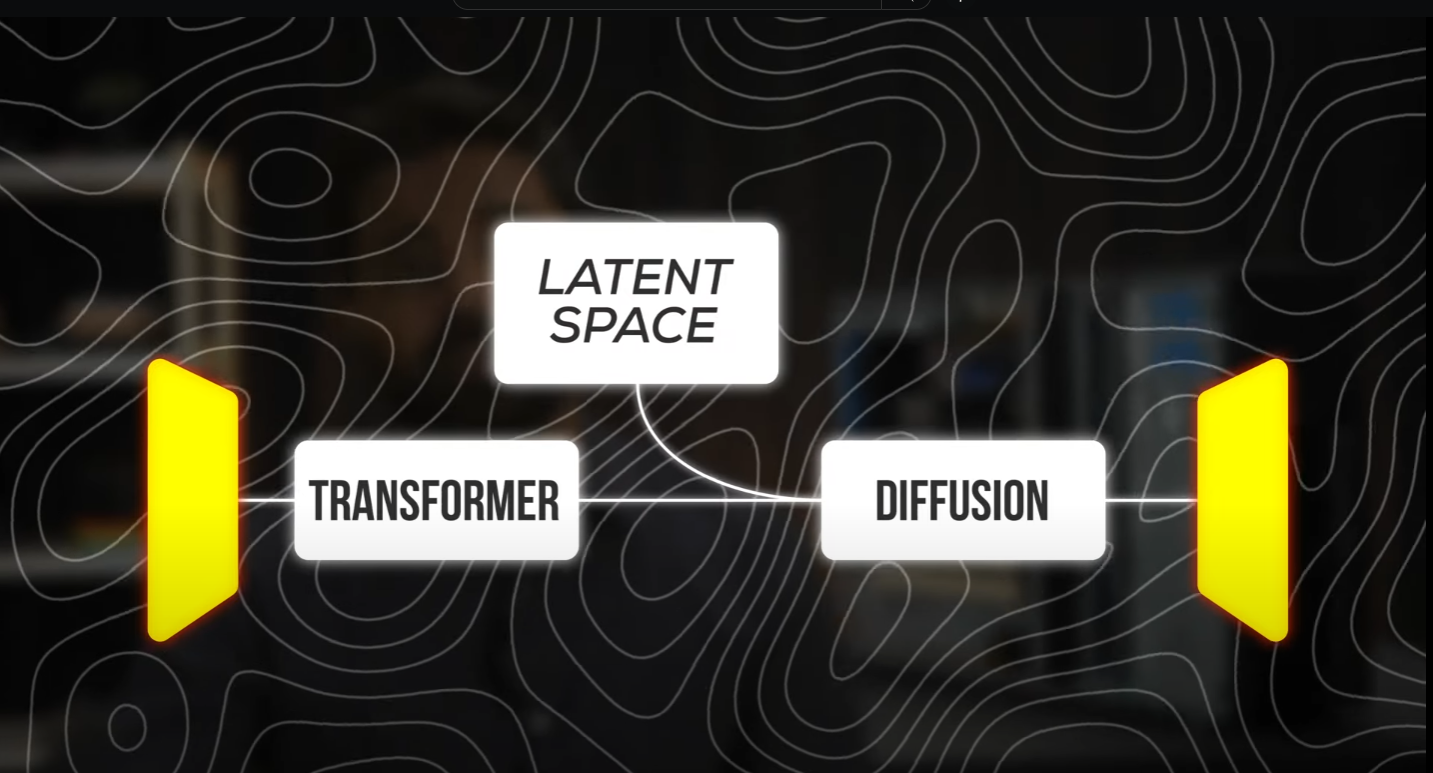

Second is Diffusion, this is the technique behind all image and video generation models.

Diffusion models are built by teaching the model to re-create all the images it has trained on – a good way to visualise is this.


If we had to differentiate between a rubber duck, and a football, the AI model looks for important factors that can help separate these images on a scale.

And the biggest difference here is colour. The model starts noticing that the duck is yellow so If we measure the amount of yellow in the images, that would put the duck at one end and the football at the other end – in this one-dimensional space.

Now, what if we add a yellow football: Now our colour metric isn’t enough.
We need a new factor. Let’s add another scale for roundness. Now we’ve got a 2D space with the round footballs at the top and the rubber ducks at the bottom.

But what if we want our model to recognize, not just ducks and footballs, but…all the other things that exist. Colour and roundness alone cannot be used to differentiate between every object in an image.
And this is exactly what diffusion models are built for – to go through all the training data and find variables that help identify objects,


they build out a relationship-graph with over hundreds and thousands of dimensions. This is called “Latent Space”
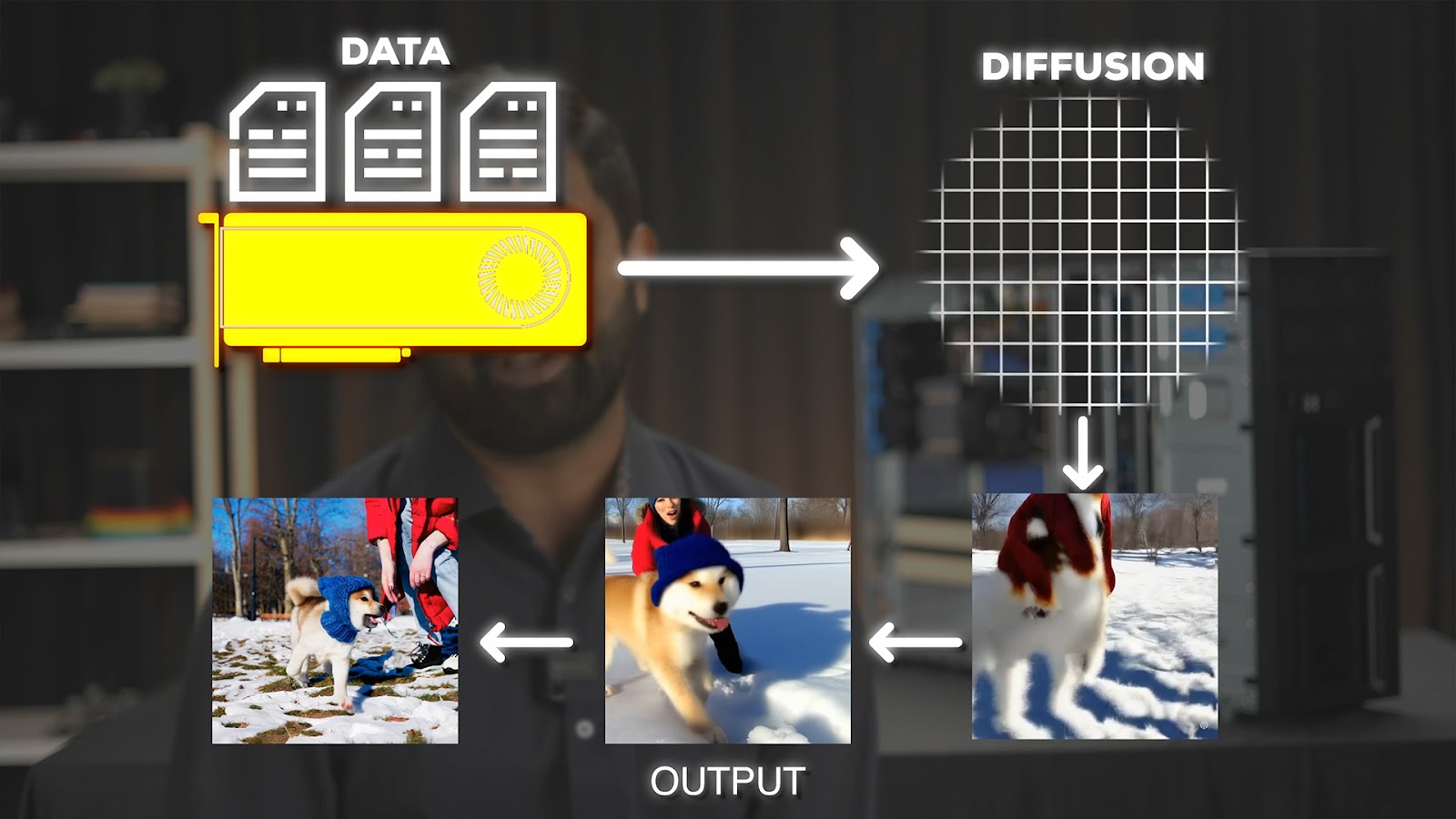
And this is just one step of the process. Once you learn image to text – now it’s time to reverse the process.

The relevant images from your “visually descriptive” prompt are taken from the “latent space” – and fed into the diffusion model with a lot of noise. To make sure we don’t create an image that already exists

And the diffusion model is already trained to denoise images. It combines these images from your prompt in a very small resolution and keeps upscaling it while referencing the real world images – to give a completely new & realistic, AI generated image.
Ok now if we replace the image latent space with video latent space – we can start generating videos right?

Well, no. You see – the biggest advantage of diffusion models is that it creates a new image every time.
And that is also the biggest problem of creating an AI video generator, you need all the frames of the video to look consistent – and not look like they were generated individually.
So how did OpenAI manage to use the same diffusion model – that wasn’t working for anyone else, and built Sora.
Well – according to them, the major difference is that their model is using something called space-time patches.
Which means apart from visual factors like colours and shapes, SORA is also learning the space-time factors like movement, fluidity and what not.
But here’s the fun part – a section in their website shows how SORA works at different levels of compute power.


And notice, at lower levels – it looks very similar to what other video generators have. And yes, it is showing signs of physics – but even other videos from other AI video models show signs of physics.
So what’s different? It’s clear actually – the GPUs…


Now, I know what you’re thinking – everybody is training AI models on GPUs, so how is OpenAI any different?
They’re different because they’re using more GPUs than any other AI company can even afford. With the help of Microsoft, ChatGPT was trained using more than 4,000 A100 GPUs.
While most other Software companies are relying on Cloud Computing Solutions – OpenAI specifically partnered with Microsoft, who partnered with Nvidia – so the OpenAI team gets unlimited Compute Power.
But why does having more GPUs mean better AI software? well to understand that – we need to know what’s so different about Generative AI models.
both the transformer & diffusion architectures have one thing in common, and that is they are extremely scalable. Which m eans – the more data & the more compute you feed, the better your model gets at recognising patterns & variables.
Another huge advantage of having your own hardware – is that you can choose the exact hardware that can give you a lot more power at a lot less price.
For example – this server we built has 2x Nvidia L40s, which is a recent release in the Nvidia Data Center GPU Lineup.
And this has a lot of features that previous GPUs like the A100 didn’t have – mainly a Transformer Engine, which is a purpose-built hardware in the L40s to boost AI models’ training and inference speed by almost 2 TIMES while costing less.
So that was everything you need to know about the new SORA – and incase you’re looking for a system to build your own AI model – you can get in touch with our subject matter experts.
Feel free to reach us out on email, toll free, whatsapp – whatever works for you and we’ll be happy to help.
Until next time, Cheers.